
O problema do fechamento automático de alertas resolvidos
Uma funcionalidade básica de bons sistemas de alerta é a capacidade de fechar um alerta automaticamente quando o problema foi resolvido (até mesmo quando o problema se resolve sozinho). Infelizmente para alertas do OpsGenie, o ElastAlert não tem essa capacidade!
Mas baseando na excelente dica encontrada aqui #337 e aqui #115, é possível criar uma regra para monitorar outra regra e com isto automatizar o fechamento automático de alertas no OpsGenie, como em:
name: Service is back online
type: flatline
index: elastalert_status*
query_key: "rule_name"
filter:
- query:
query_string:
query: "rule_name:\"RULE_NAME_HERE\" AND matches:>0"
forget_keys: true
timeframe:
minutes: 10
threshold: 1
alert:
- "opsgenie"
opsgenie:
opsgenie_addr: <ALIAS NAME HERE>/close?identifierType=alias
opsgenie_key: ${OPSGENIE_API_KEY}Onde em:
RULE_NAME_HERE: o nome da rule em que se deseja fechar os alertas já resolvidos.<ALIAS NAME HERE>: o alias do alerta no OpsGenie.
Mas esta solução funciona muito bem apenas para o fechamento de alertas que monitoram um único serviço.
Em cenários onde temos uma única rule para monitorar um conjunto variado de objetos (agregados e diferenciados por nome, e com alias do Opsgenie diferentes, como o abordado aqui), a solução acima não funciona (pois se múltiplos alertas forem disparados ele não saberá qual terá que fechar).
Para que seja possível, teríamos que ter a capacidade de fazer consultas aos campos do objeto match_body no índice elastalert. Mas por padrão esse campo não é "consultável", pois possui a indexação de seus campos desativada.
Outro empecilho é a atual integração com o OpsGenie não permitir a interpolação do endereço da API com variáveis.
Então o plano é: ativar a indexação de campos do objeto match_body e criar um script que executa um curl para o fechamento do alerta já resolvido. E aí sim conseguir criar uma regra de fechamento de alertas para o nosso cenário que executa como comando o script de fechamento de alertas.
A resolução desse problema pode ser vista no diff deste commit, onde foram feitos os seguintes passos:
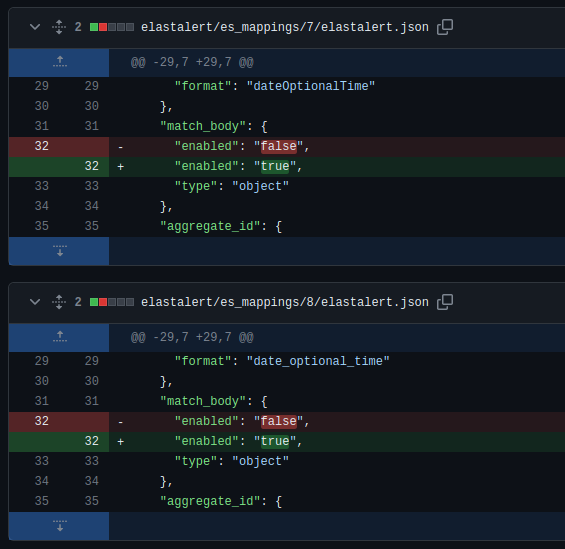
1) Habilite o mapping de campos do objeto match_body:
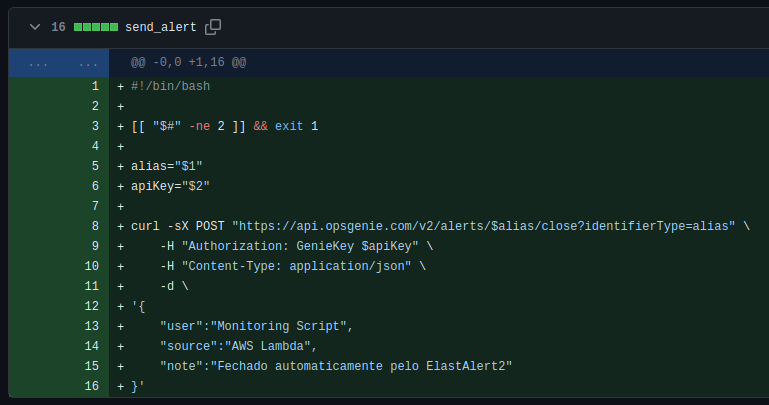
2) Crie um script que receba o "alias" e a "apiKey" do Opsgenie e execute um curl para fechar o alerta:
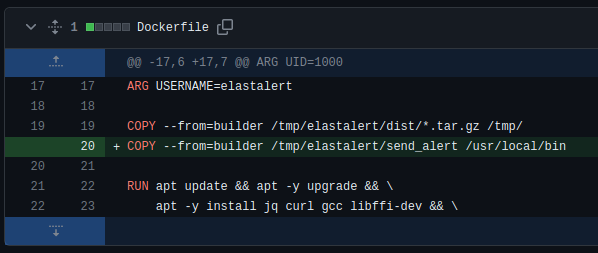
3) Altere o Dockerfile para que ele inclua o script:
 Use um alerta do tipo
Use um alerta do tipo "command" para chamar o script. Exemplo:
name: Deployment is back online
type: flatline
index: elastalert
query_key: "match_body.kubernetes.deployment.name"
use_terms_query: true
doc_type: _doc
filter:
- query:
query_string:
query: "rule_name:\"k8s Deployment Monitoring\" AND match_body.num_matches:>0"
forget_keys: true
timeframe:
minutes: 11
threshold: 1
alert:
- "command"
command: ["/usr/local/bin/send_alert", "%(key)s", "${OPSGENIE_API_KEY}"]Um exemplo completo seria algo como:
k8s_deployment: |-
---
name: k8s Deployment Monitoring
type: frequency
index: metricbeat*
num_events: 59
timeframe:
minutes: 10
metric_aggregation:
query_key: kubernetes.deployment.name
filter:
- query:
query_string:
query: "kubernetes.deployment.replicas.available: 0 AND kubernetes.deployment.replicas.desired:>0 AND (agent.name: cluster01 OR agent.name: cluster02 OR agent.name: cluster03)"
alert:
- "opsgenie"
realert:
minutes: 60
opsgenie:
opsgenie_subject: "[Elastic Observability] {0}: Deployment Pods Available = 0.0 for at least 10 minutes on '{1}'"
opsgenie_subject_args:
- agent.name
- kubernetes.deployment.name
opsgenie_priority: "P1"
opsgenie_alias: "{kubernetes[deployment][name]}"
opsgenie_addr: https://api.opsgenie.com/v2/alerts
opsgenie_key: ${OPSGENIE_API_KEY}
k8s_deployment_ok: |-
---
name: Deployment is back online
type: flatline
index: elastalert
query_key: "match_body.kubernetes.deployment.name"
use_terms_query: true
doc_type: _doc
filter:
- query:
query_string:
query: "rule_name:\"k8s Deployment Monitoring\" AND match_body.num_matches:>0"
forget_keys: true
timeframe:
minutes: 11
threshold: 1
alert:
- "command"
command: ["/usr/local/bin/send_alert", "%(key)s", "${OPSGENIE_API_KEY}"]Last updated